简介
⽂本定位主要适⽤于识别图⽚中⽂本的位置信息。利⽤计算机视觉智能识别图⽚中的⽂本信息并进⾏定位,⽣成的带有类别信息的⽬标候选框,经常应⽤于带有多种⽂本信息的票据,证件识别中。本文主要介绍如下两种文本定位算法:
- Deeptext
- CTPN
Deeptext
Deeptext算法原理
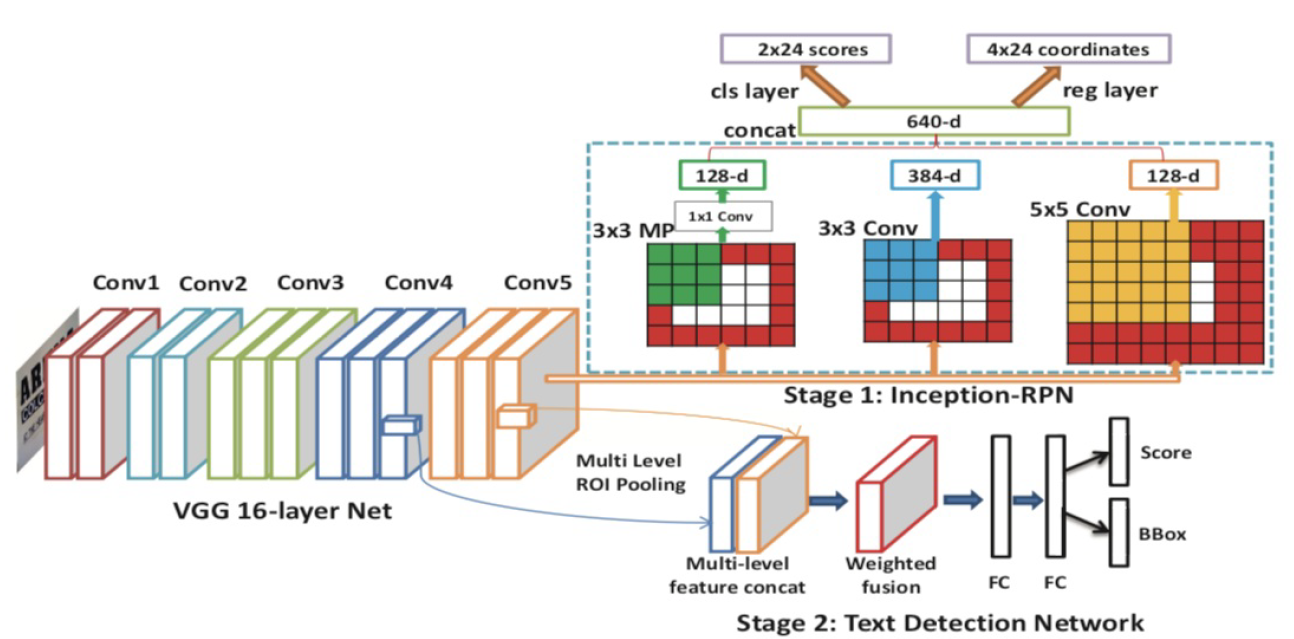
DeepText是基于Faster R-CNN针对⽂本定位进⾏改进的Two-Stage模型。DeepText的结构和Faster R-CNN如出⼀辙:⾸先特征层使⽤的是VGG-16,其次算法均由⽤于提取候选区域的RPN和⽤于物体检测的Fast R-CNN。关于上述几个结构与概念,有相关卷积神经网络结构和本博客相关文章如下,建议在看本文之前先行阅览:
DeepText的创新点
- Inception-RPN:与传统RPN相⽐,使⽤3x3的max pooling, 3x3的卷积以及5x5的卷积,使得在RPN模块可以考虑多尺度的特征;
- ATC: ⽂本与其他物体检测不同的是很多置信度在[0.2,0.5]的框内也是有⽂本存在的(物体检测⼀般将置信度⼩于0.5的样例当作负样例),这样就会将很多⽂本当作负样例,影响最终的结果。所以DeepText在RCNN的分类结果中加⼊了ATC的分类(正、ATC、负);
- MLRP:在Detection Network模块中使⽤来⾃不同卷积层的特征,因为不同层的特征不同,融合多种特征可以提升指标;
- IBBV:使⽤多个Iteration的bounding boxes的集合使⽤NMS;
- Scales:针对⽂本特征修改超参数,⽀持(2,3,4,5)四种scale;
- Ratios:针对⽂本特征修改超参数, ⽀持(0.2, 0.5, 0.8, 1.0, 1.2, 1.5)六种scale;
DeepText的⽹络结构
指标介绍
验证指标
⽂本定位验证指标主要是计算预测出来的物体的位置的框与真实的框之间的精确率(precision),召回率(recall), F值(F-Measure),相关的定义如下:
- 精确率:预测为某类样本(例如正样本)中有多少是真正的该类样本。
- 召回率:样本中的某类样本有多少被正确预测了。
- F值:P和R指标有时候会出现的⽭盾的情况,这样就需要综合考虑他们,F-Measure是Precision和Recall加权调和平均。
训练指标
- 训练总损失: ⽂本定位的验证指标主要是训练损失,代表了真实值和预测值之间的差值,如果训练损失越来越⼩,代表模型预测的能⼒越来越强。
- 训练准确率: 训练准确率则代表着训练集上被预测准确的样本数占总样本的⽐例情况;
CTPN
算法概述
CTPN是基于Faster-RCNN针对⽂本定位进⾏改进的Two-Stage模型。 CTPN的结构如Faster R-CNN如出⼀辙:⾸先特征层使⽤的是VGG-16,其次算法均由⽤于提取候选区域的RPN和⽤于物体检测的Fast R-CNN。DeepText的创新点如下:
- BLSTM:CTPN结构与Faster R-CNN基本类似,但是加⼊了LSTM层。该循环⽹络层采⽤双向LSTM,使得⽹络学习到了⽂字前向、后向的序列信息,但是训练过程需要⼩⼼梯度爆炸。
- 定宽的anchor: 由于CTPN针对的是横向排列的⽂字检测,所以其采⽤了⼀组(10个)等宽度的Anchors,⽤于定位⽂字位置。Anchor宽⾼为:width = [16] ,height = [11,16,23,33,48,68,97,139,198,283];该设置⽅法保证了在x⽅向上,Anchor覆盖原图每个点且不相互重叠,并且anchor⾼度覆盖了不同尺度⽂本⽬标。
- ⽂本线构造:在获得多个text proposal的基础上,需要将各个group的proposal进⾏合并,即将定宽proposal链接成标准框,主要利⽤计算overlap以及⽔平正向距离确group,再执⾏框链接算法;
指标介绍
验证指标
⽂本定位验证指标主要是计算预测出来的物体的位置的框与真实的框之间的精确率(precision),召回率(recall), F值(F-Measure),相关的定义如下:
- Precision:预测为某类样本(例如正样本)中有多少是真正的该类样本。
- Recall:样本中的某类样本有多少被正确预测了。
- F-Measure:P和R指标有时候会出现的⽭盾的情况,这样就需要综合考虑他们,F-Measure是Precision和Recall加权调和平均。
训练指标
⽂本定位的验证指标主要是训练损失,代表了真实值和预测值之间的差值,如果训练损失越来越⼩,代表模型预测的能⼒越来越好。
